
When this article was published ConCache was an active project. Since then Cachex has replaced it. It is very similar, so most parts of this article are still valid/useful.

An API project I have been working on recently uses a plug to get the current user and authenticate them. This is not uncommon, but as a user navigates through the application, they will be authenticating on every request. In the interest of performance, I wondered if we could do better.
First, let me describe what the authentication plug does. It pulls the user id from a JWT. Then it queries the local database for that user and loads the user attributes as well as preloading an association. Last, it stores that data in the conn. In some of our controllers we will pull that user data from the conn rather than making additional queries.
The problem
The issue is that to build the front-end of the application we may hit 3 or more API endpoints for each rendered page. This means for each URL the user requests, we are potentially authenticating them 3 or more times. That is 3 round trip queries to the database before the user sees anything.
In the interest in making the system more efficient , and thus faster, I started investigating a caching strategy for that plug. The solution I ended up with starts with a library created by Saša Jurić called ConCache.
Using ConCache
ConCache implements an ETS based key/value storage with the following additional features:
- row level synchronized writes (inserts, read/modify/write updates, deletes)
- TTL support
- modification callbacks
In this case, it takes the results of my query (which is a user struct with a preloaded association struct) and stores that entire term as the value in a row in ETS. The key is the user id.
Implementation is quite simple.
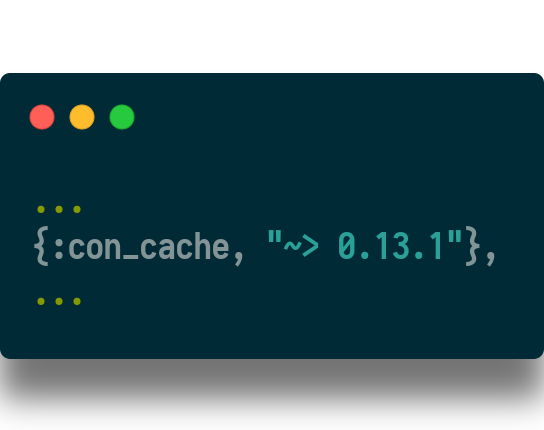
Step 1. Add the library to mix.exs
Step 2. Add ConCache to the application supervisor
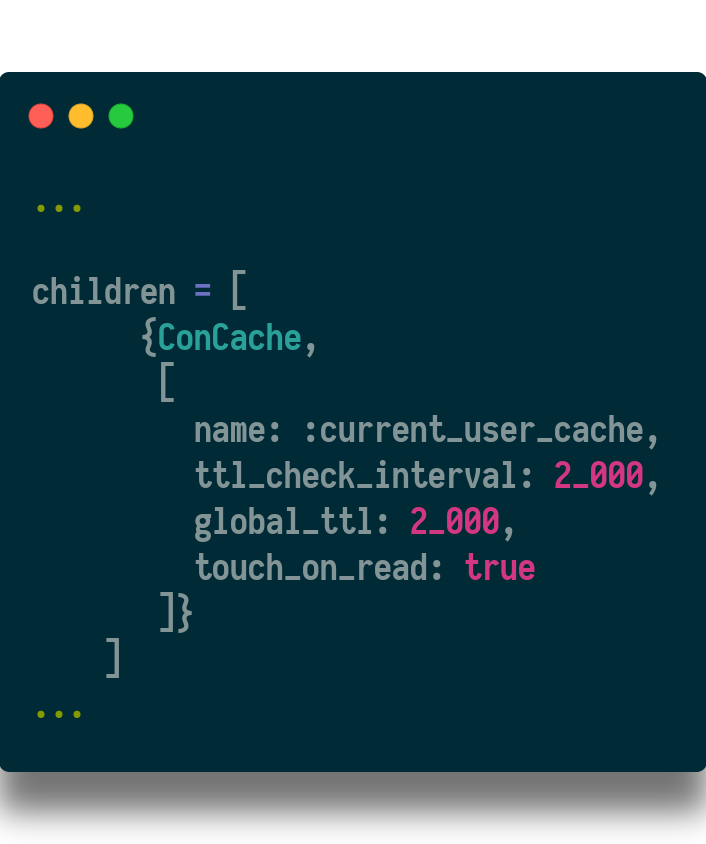
The options passed are:
- name: The name of the ETS table storing this cache
- ttl_check_interval: the interval time, in ms, for the process that manages clearing expired caches
- global_ttl: the lifespan of each row in the cache
- touch _on_read: resets the global_ttl when the cache is hit
Some further explanation; There is a heartbeat process that checks each cache for expired rows. The interval between beats is the ttl_check_interval. So, every 2 seconds this process fires off and looks for caches to delete.
The global_ttl sets that expiration time on each row. Essentially the time it was created plus 2 seconds.
And the touch_on_read option resets that expiration time every time you read from that cache row.
What this means is that if you hit the cache at least once every 2 seconds the cache could never expire. Also, since the expiration is 2 seconds and the heartbeat is 2 seconds, the longest a row can live without being touched is 4 seconds (well, 3,999 ms technically.)
The next step in implementation is to replace the lookup query with code that checks the cache first. In the auth plug, replace this code:
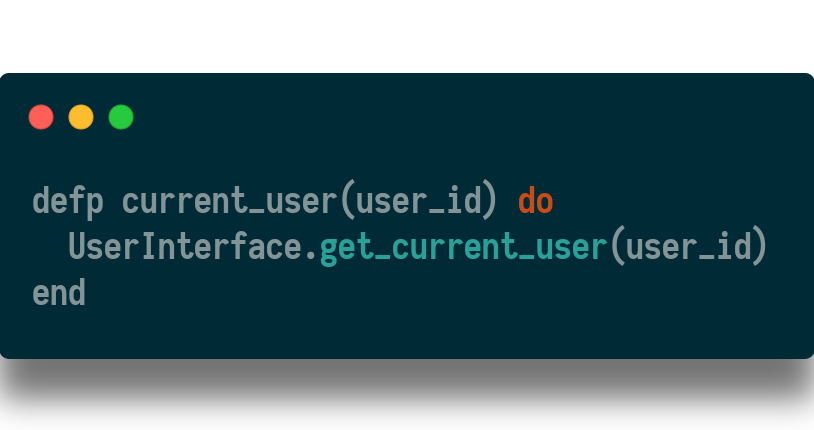
with this code:
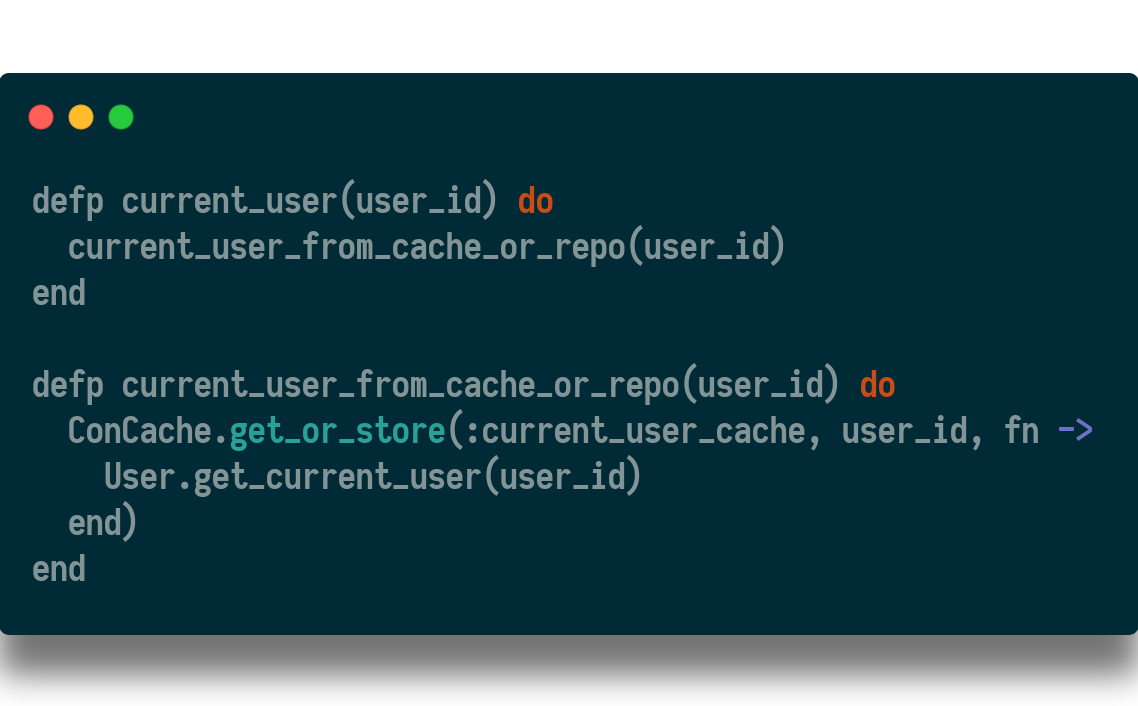
This uses the ConCache get_or_store/3 function to attempt to lookup the result in the cache first, and if it is not found, look it up in the database and save that to the cache.
And finally, some code to manually delete cache rows when the user is mutated:
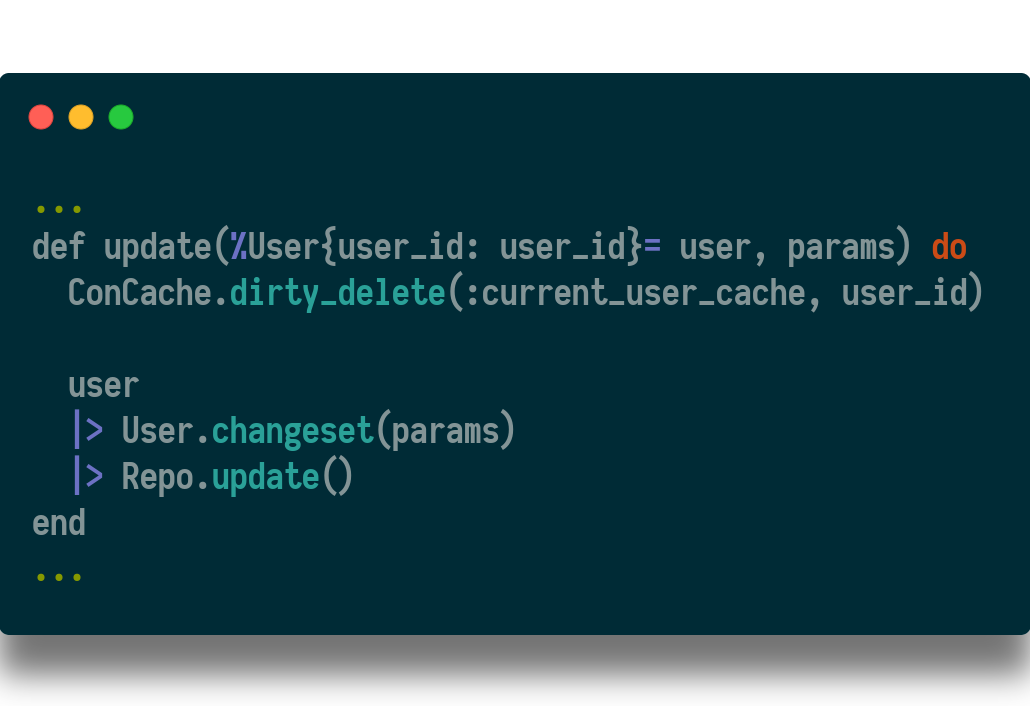

Uh oh…
At this point, I ran into an immediate problem. My integration tests were reusing the same user id and ended up reading from the cache instead of the user i created in the factory for each test.
There are at least three ways to attack this problem;
- do not reuse user ids in tests
- expire the cache manually after every test
- turn off caching in the test environment
Of these, I decided option 3 was the easiest and made the most sense. Given the number of tests I had failing this solution resulted in the least amount of new code.
So, how did I turn off caching in the test environment?
I abstracted the calls to ConCache to go to a local defined cache store instead. In config, the @cache_store is set to ConCache. In the config/test.exs file it points to a module I defined:
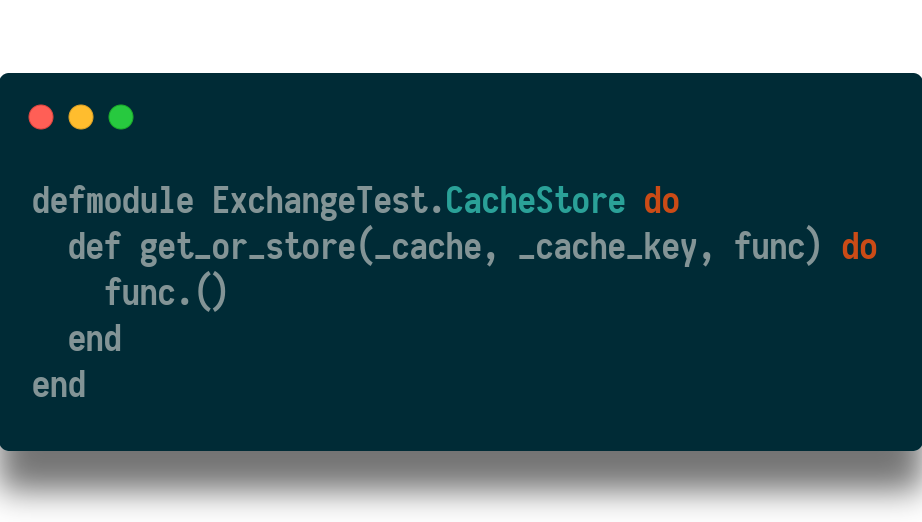
This local module maintains the interface ConCache has, but it’s definition will always just call the anonymous function passed in as the third argument. Essentially, it just doesn’t even look in the ETS cache.
Problem solved
At this point, if you are running your application on a single node your work is done.
In my initial testing, I have seen the applications throughput increase by 6–8%. That is without any tuning. Keep in mind, I have introduced a new process that runs every 2 seconds, which will effect CPU load. Also, the cache is expiring every 2 seconds. It is possible a longer TTL will improve performance even more.
More gotchas
Unfortunately for me, my app is running on multiple nodes behind a load balancer. Since the two nodes aren’t aware of each other, the cache on node A can diverge from the cache on node B for the same user id. Imagine navigating around the site and half the screens show your old username and half show your new one 😕.
Solving the diverging cache issue requires alerting every instance of the app whenever a mutation takes place to an object that could be cached. In my case, whenever a user is updated.
Admittedly, there are many ways to do this, but the way I decided on was to leverage my relation database (postgres.) If you haven’t discovered by now, postgres can do just about anything.
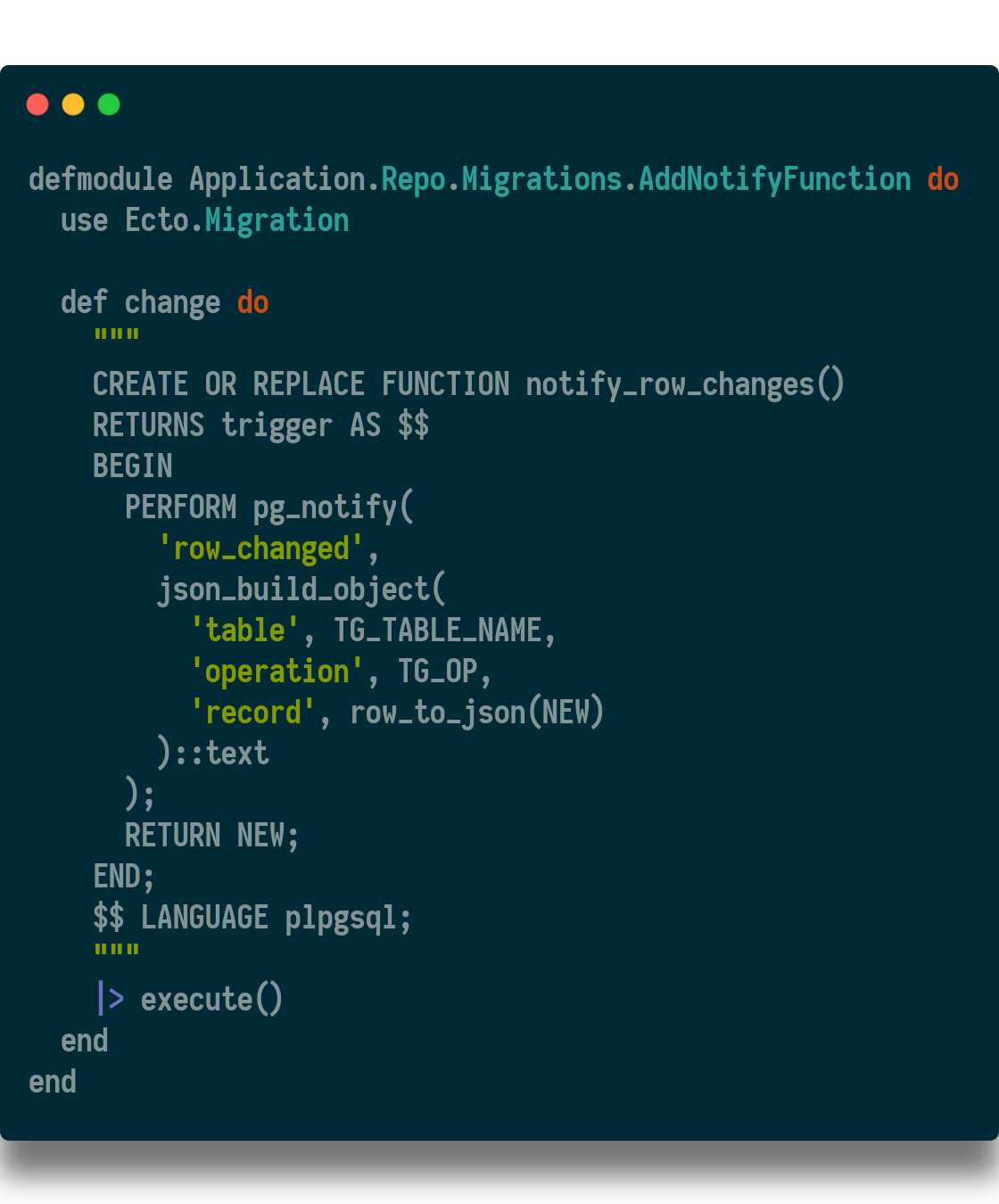
Specifically, the strategy is to have the database send a message to each instance of the app whenever a user changes. Since each instance is already connected to database, this felt like a logical approach.
To do this, I added a function to the database that uses PG_NOTIFY to send a message with metadata about a query. This message will be in json format, and have 3 keys and values; the table name, the operation (update), and the entire row from the query.
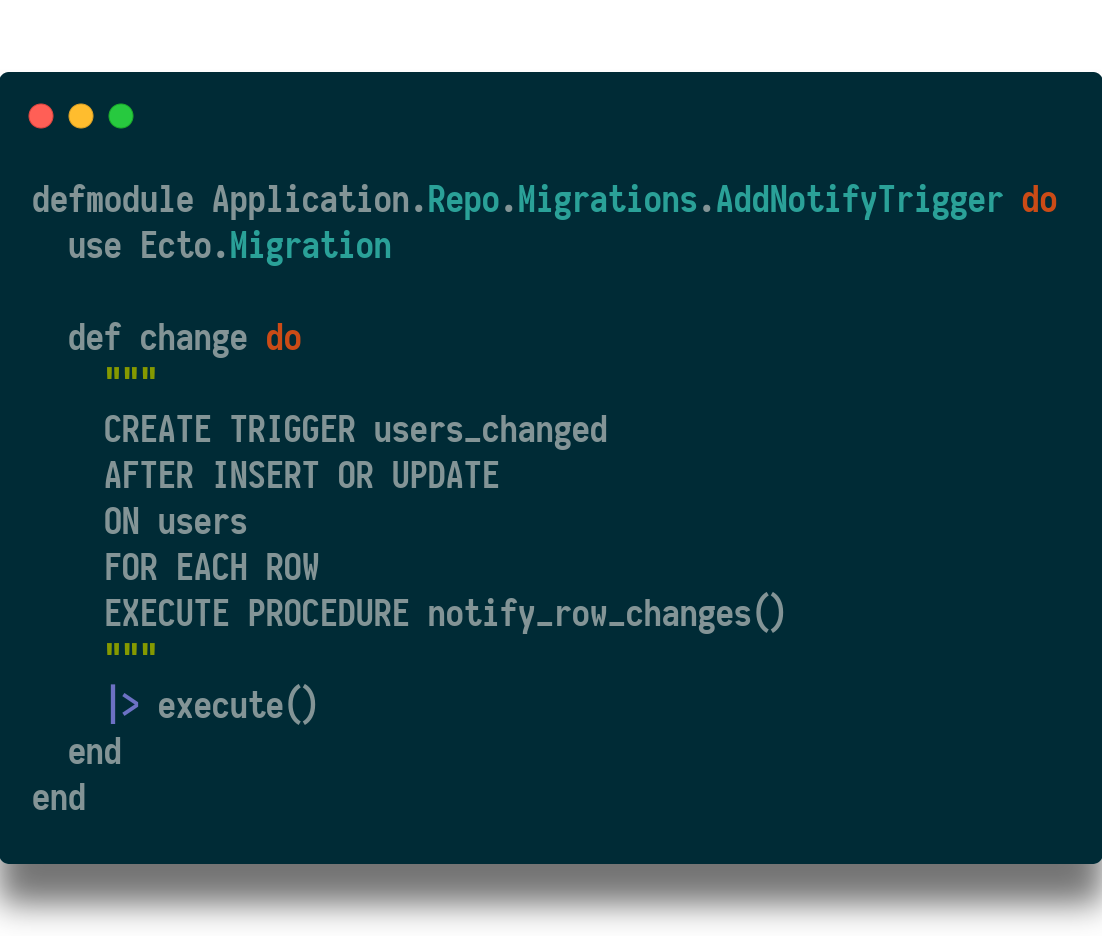
Then I created a trigger to call that function whenever a user is updated.
And finally, I added some code to my application to accept those messages from the database and take action on them.
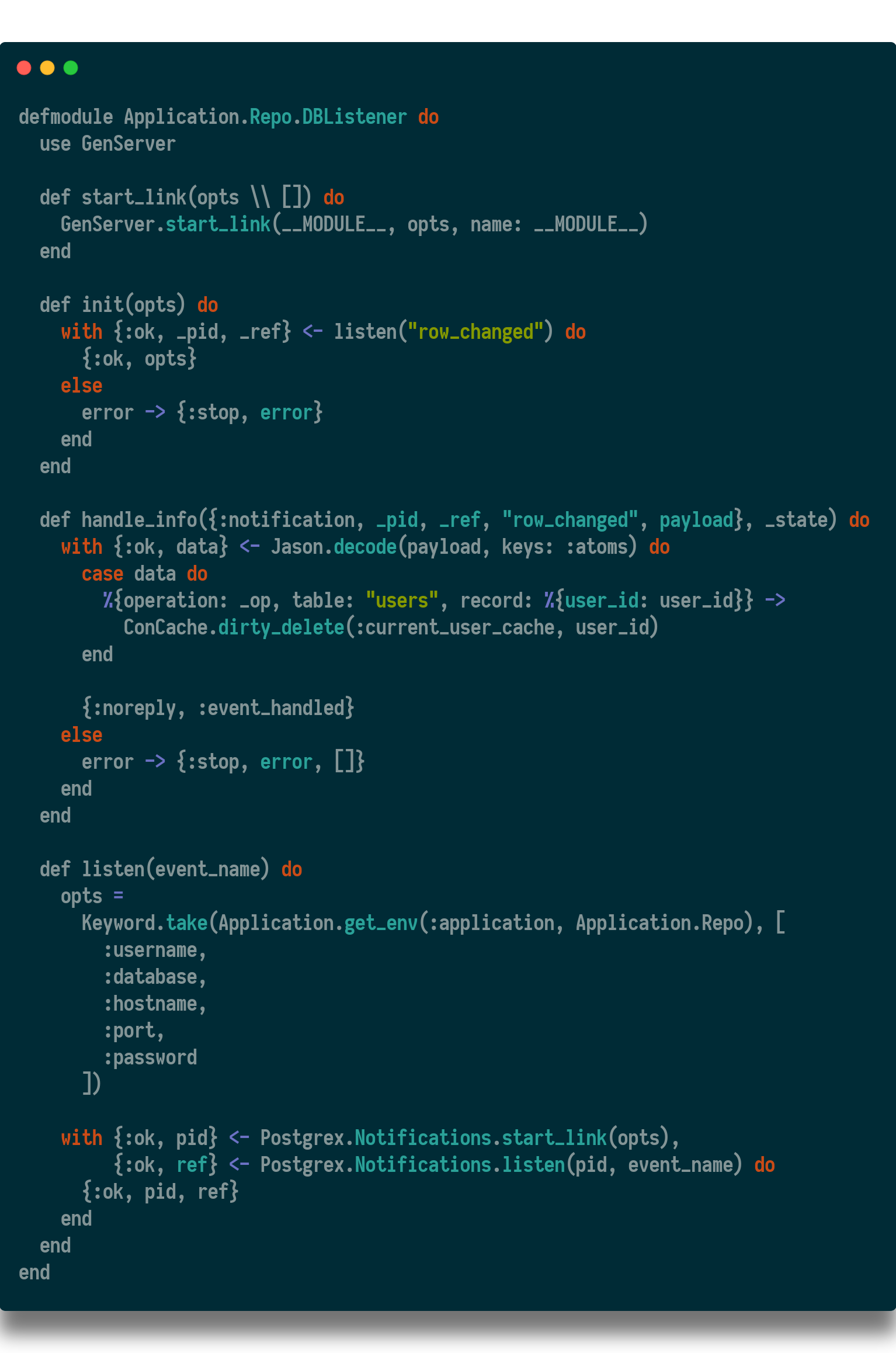
And add this genserver to the application supervisor.
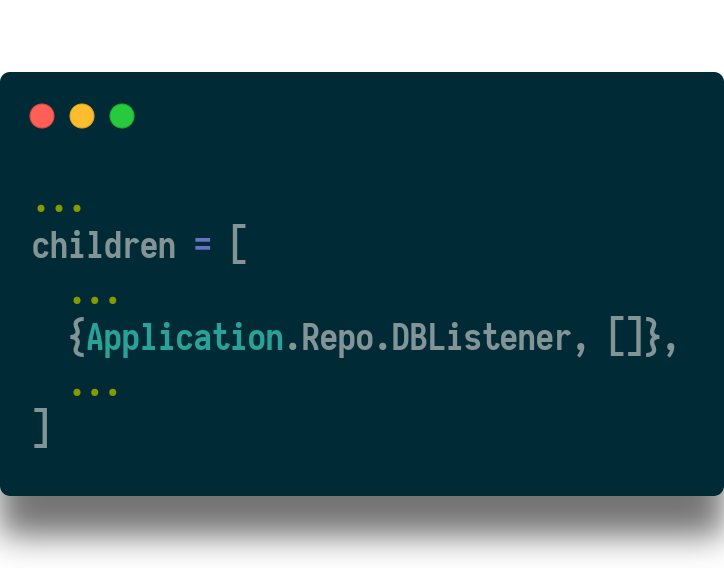
Ok, now each instance of the app will delete its cache of a user row when any mutation is made on that user. This is somewhat naive, since it is possible to just update the cache when an update takes place. But this is a safe approach for an initial implementation.
Thank you
Thanks for reading. If you are interested in my mental well-being, jam on the clap button.