

If you have even a cursory knowledge of the Bible, you might recognize that tongue-in-cheek title paraphrased from Philippians 4:13. While I chose it because I thought it was catchy, it is also fair to say many developers have a religious affinity for certain databases.
The Purpose
The goal of this post is to shed some light on another way of thinking about development problems. As you’ll see, these problems could all be solved with Elixir code. I want to give some concrete examples of problems that are better solved with the database.
Advantages
There are some problems Postgres is just better at solving. Since it was introduced over 20 years ago, a lot of work has gone into adding features and performance.
In addition, I have seen a lot of projects where the application CPUs are constantly under load and the DB server CPU hovers around 5%. All things being equal, these techniques must just be good for redistributing load across your resources.
Ecto
All of the examples assume you are using Ecto, but the concepts can easily be ported over to other systems. Moving logic into Postgres does not mean ditching your ORM. Thankfully, through a combination of migrations and fragments, we can inject SQL sparingly to accomplish our goals.
Complex Constraints
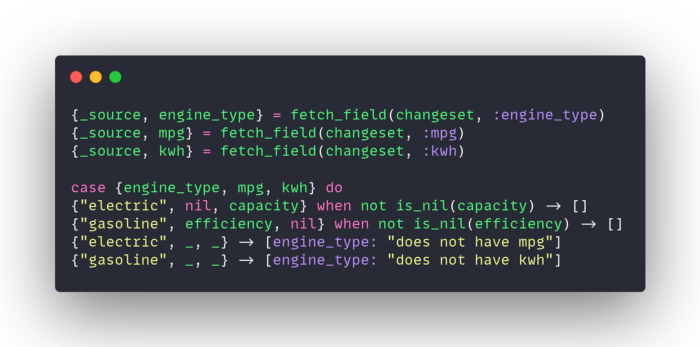
In this example, the schema represents a car. There are 3 columns: engine_type, mpg, and kwh. A car should never have data in all 3 fields. Only a car with an electric motor should have kwh. And only a gasoline engine should have mpg.
Let’s say you want to make sure that logic is validated in a changeset, you might create a custom validator like this:
Using postgres, the migration gets a new check constraint. Supporting this constraint only requires adding a check_constraint/3 function to the changeset. With this strategy the database will ensure the business logic is followed and the changeset will return a useful error if it doesn’t.

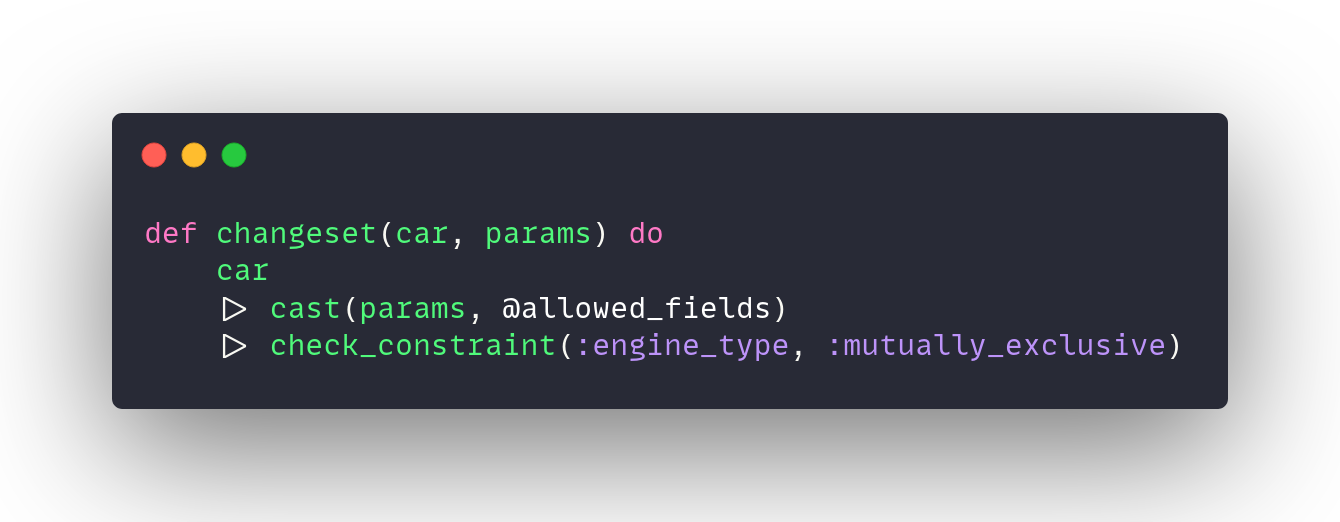
In addition, all data in the database will be validated. Even if it doesn’t go through the changeset (maybe you imported data from an external source.) I think it’s common to take a belt-and-suspenders approach to data validation by validating on the front-end as well as the back-end. Adding this type of validation at the db level is belt-and-suspenders-and-an-elastic-wasteband.
Citext
Citext is an extension to postgres. It adds a new datatype that is essentially a case-insensitive string. Installing it is very easy (as you can see below.)

Under the hood, postgres is actually converting both sides of the query to lowercase. Incidentally, this is generally what you would do in your application code to achieve the same end.
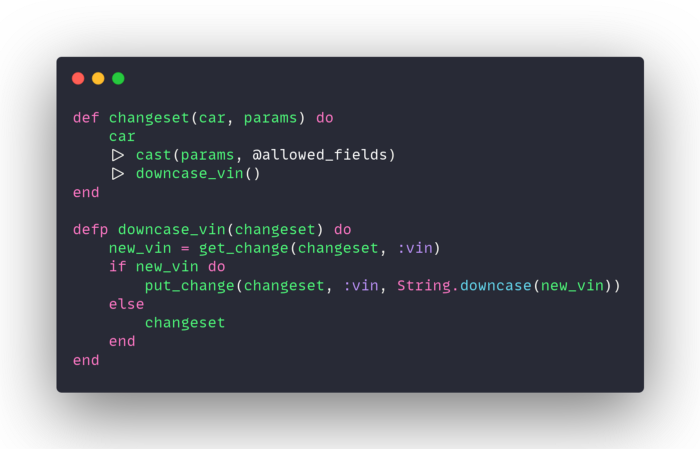
As you can see, the elixir code required to perform a case-insensitive search is a bit more complex. In addition, if you decided to add this to an existing database you would need to migrate all of the existing data. Using Citext doesn’t have that requirement.
Adjacent Rows
Let’s say your users search for cars based on price. You want to show them the cars that are exactly the price they asked for, but also some cars that are a little more and a little less. In elixir, that might mean getting 3 lists of results and merging them.
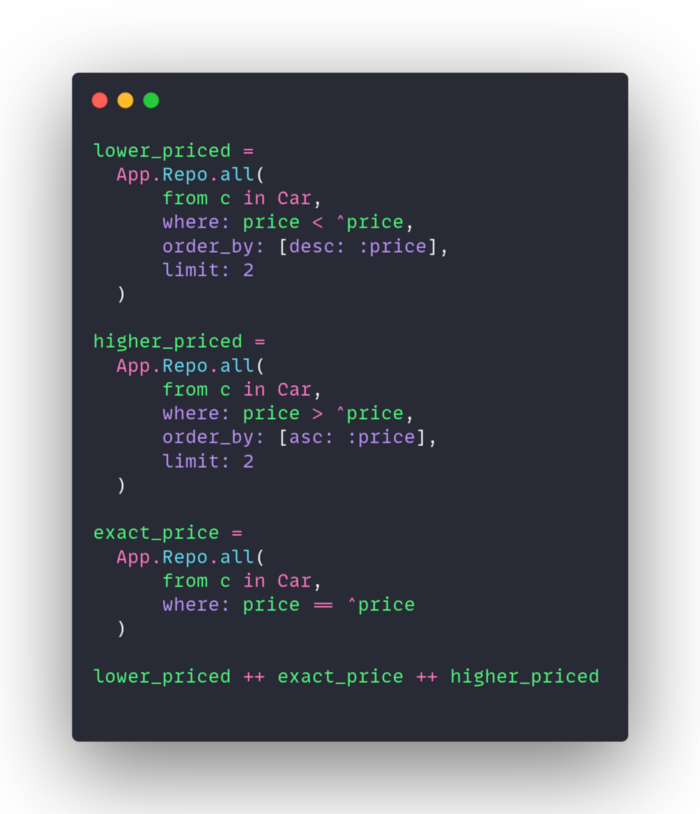
Postgres is storing data in order already. Using the window functions lag and lead, you can have postgres target the exact match and then just grab the rows around it in the index. Think of this like going to a car lot where every car is parked in order of price. If you start out at the $5,000 car, the ones close in price will be parked right next to it.
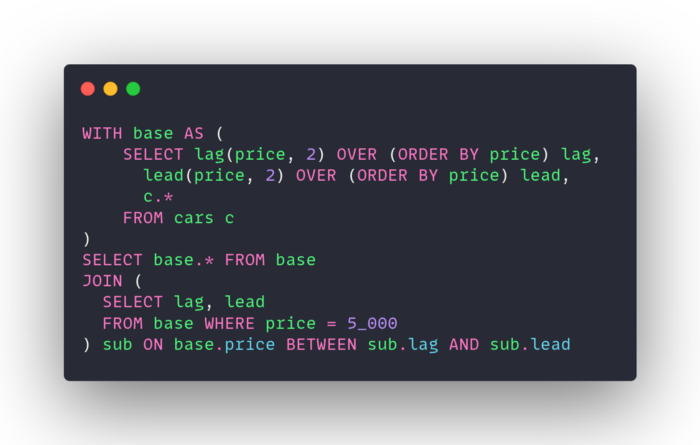
Common Table Expressions
In the above example you can also see the use of CTEs. The top section (starting with “WITH”) defines the CTE used in the query.
A CTE is a temporary result set which you can reference within another SQL statement including SELECT, INSERT, UPDATE, or DELETE. It is useful anytime you would have a recursive query.
String searches
Searching for fuzzy matches can be very inefficient in elixir. Let’s say you wanted a text search that looks at both the car’s make as well as it’s model. In addition, you want to return near matches in case the user misspells the name.
In elixir, you might need to load every car, then iterate over each (twice) to calculate the string similarity and to sort the results. In this example, we are using the jaro_distance which is available in the String module.
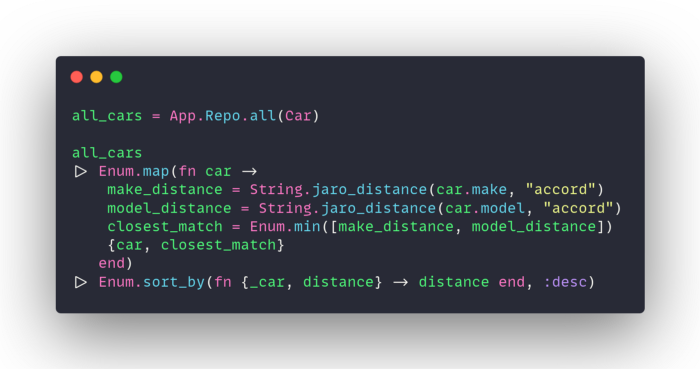
By moving that logic into the database query we can use functions that are built in to postgres. Levenshtein distance calculation is available in postgres without the need for any plug-ins.

In conclusion
I have just scratched the surface of the capabilities of postgres. I hope I have given you some ideas on how to leverage this very powerful tool you already have installed.
Postgres has a lot of strengths when organizing, querying, and transforming data (that’s kind of what it was designed for.) There are definitely a time and place to leave logic in your application, but I hope you will at least consider how moving logic into postgres could help you.
Some of the features I left out include views, triggers, and pg_notify. If those interest you, check out my article on caching an elixir app.